Understanding AI Agent using Pure Typescript, No Framework

What project will we build
ผมจะทำ project ง่ายๆครับ เป้าหมายเพื่อให้เข้าใจ การทำงานของ AI Agent ด้วย typescript เท่านั้นครับ
เพื่อนๆแค่พอใช้ Typescript ได้ ใช้ Rest api ได้ก็น่าจะพอเข้าใจได้ไม่ยากแล้วครับ
ผมจะไม่ได้ใช้ lib อะไรเพิ่มเลย พยายามทำให้มัน basic ที่สุดครับ
แล้วผมจะทำอะไร
ตัว project จะเป็น user ส่งคำถามเกี่ยวกับ ราคาปัจจุบันของ Crypto ไปที่ LLM ผ่าน Ollama นะครับ
โดยจะถามราคาเป็นภาษาพูดของมนุษย์ แล้วเราก็มี function ที่เอาไว้ดึง data จาก KuCoin Api
สิ่งที่เราจะต้องทำคือ ส่ง function ไปให้ LLM มันรู้จัก แล้วเอาราคาของ crypto มาตอบเรา
โค้ดทั้งหมดอยู่ใน github repo นี้ครับ
KuCoin api
มารู้จักกับ KuCoin api กันก่อน
มันใช้งานฟรี ผมก็เลยเลือกอันนี้
ส่วนราคาถูกต้องแค่ไหนผมก็ไม่รู้นะ
ยิง base กับ currencies ไปที่
https://api.kucoin.com/api/v1/prices?base=USD¤cies=BTC,ETH,BNB,NEAR,SOLbase
- USD
- THB
- EUR
api นี้จะ return data แบบนี้
{ "code": "200000", "data": { "BTC": "107760.9750199141576073", "SOL": "150.8250810000005476", "BNB": "649.0719007000192164", "ETH": "2438.6138370001520988", "NEAR": "2.1230122800000000" }}Setup Ollama
อยากที่บอกว่าเราจะใช้ Ollama inference นะครับ
ไปติดตั้งได้ตามนี้ครับ https://ollama.com/download
ส่วนผมใช้ Homebrew ในการติดตั้งครับ
ผมใช้ model ที่ชื่อว่า llama3.2:3b กับ qwen3:8b นะครับ
ถ้าเพื่อนๆอยากใช้ตามก็ไปสั่ง download ได้เลยครับ
ขนาดมันหลาย GB อยู่นะ
ollama pull llama3.2:3bollama pull qwen3:8bถ้าพร้อมแล้วก็สั่ง
ollama startหน้าจอ terminal มันจะวิ่งๆเป็น interactive ก็ปล่อยมันไปครับ
ollama มันก็จะพร้อมรับ request ที่ http://localhost:11434
เดี๋ยวมันก็จะพ่น log ออกมาเรื่อยๆ
Structured output
เป็นการทำให้คำสั่งของคนเราที่เราพูดๆกันปกติ กลายเป็น json ได้ โดยผ่าน LLM ให้มันแกะให้
กดดูตัวอย่างของ Structured output example from OpenAI
LLM มันก็จะแกะคำสั่งของเราแล้วเอามาสร้าง json ให้เรา แต่ก็มีจุดที่ต้องกังวล เพราะว่า LLM มันก็อาจจะเอา data มาใส่ให้เราผิดได้ เพราะอาการหลอนของมัน
แต่มันจะมี LLM ที่ถูก train ให้ทำงานนี้มาแล้วด้วย ปัจจุบันนี้ก็มีหลายตัวเลย
ส่วน model ตัวไหนที่ถูก train มาแล้วบ้าง
ถ้าเปิดที่ Ollama website ก็พอดูได้คร่าวว่ามันมี
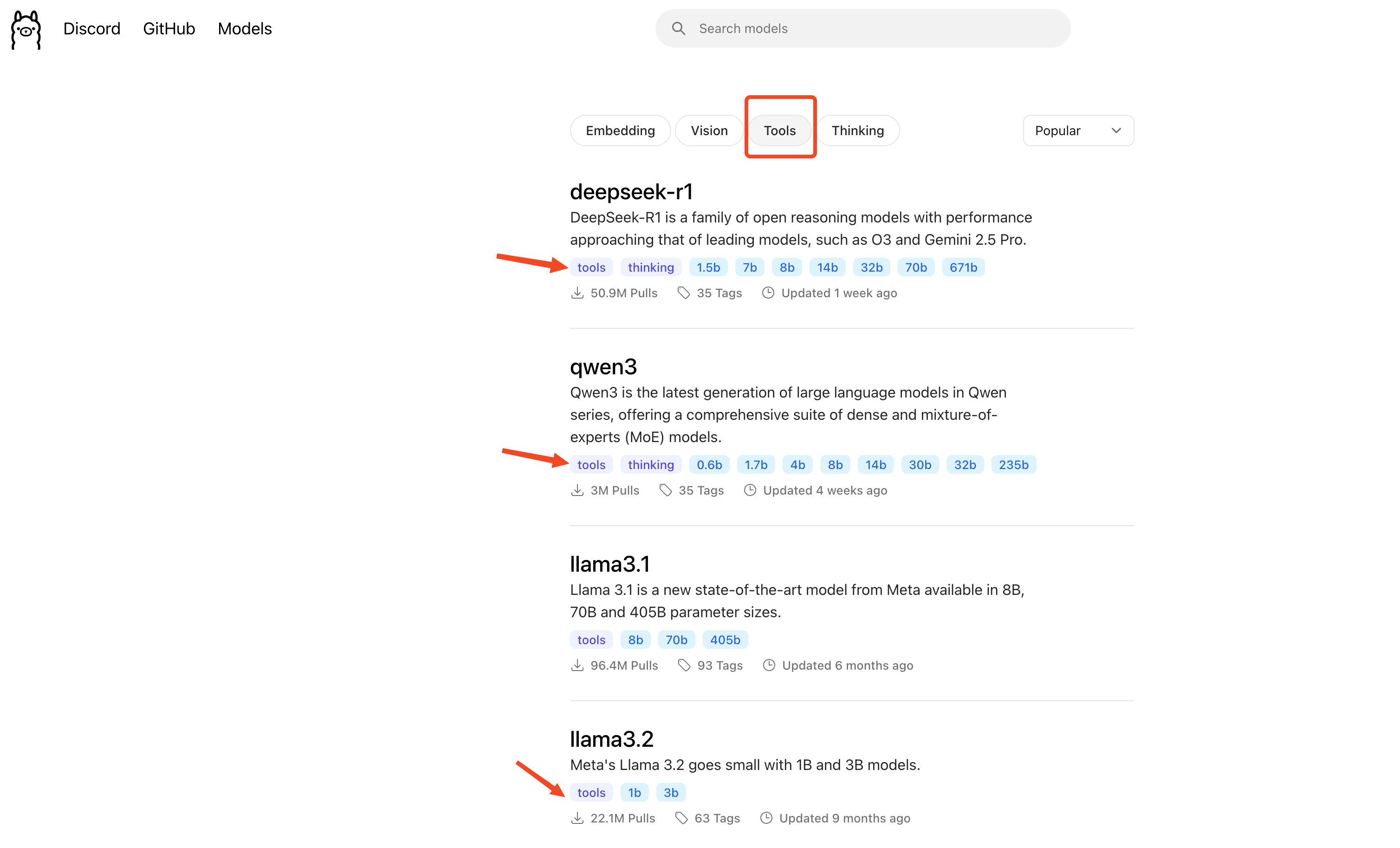
พอเอามาใช้ถ้า Model มันไม่ support มันก็จะบอกครับ
มาดูตัวอย่าง ผมอยากจะถาม LLM ว่า
“What’s the price of Bitcoin?“
structured-output.ts
const userQuery = "What's the price of Bitcoin?";แต่ว่า api ของเราต้องการแค่ Symbol ซึ่ง Bitcoin ก็คือ BTC
สิ่งที่เราต้องทำคือให้ llm มันแกะคำสั่งออกมาว่า symbol มันคืออะไร และให้มัน response กลับมาเป็น json
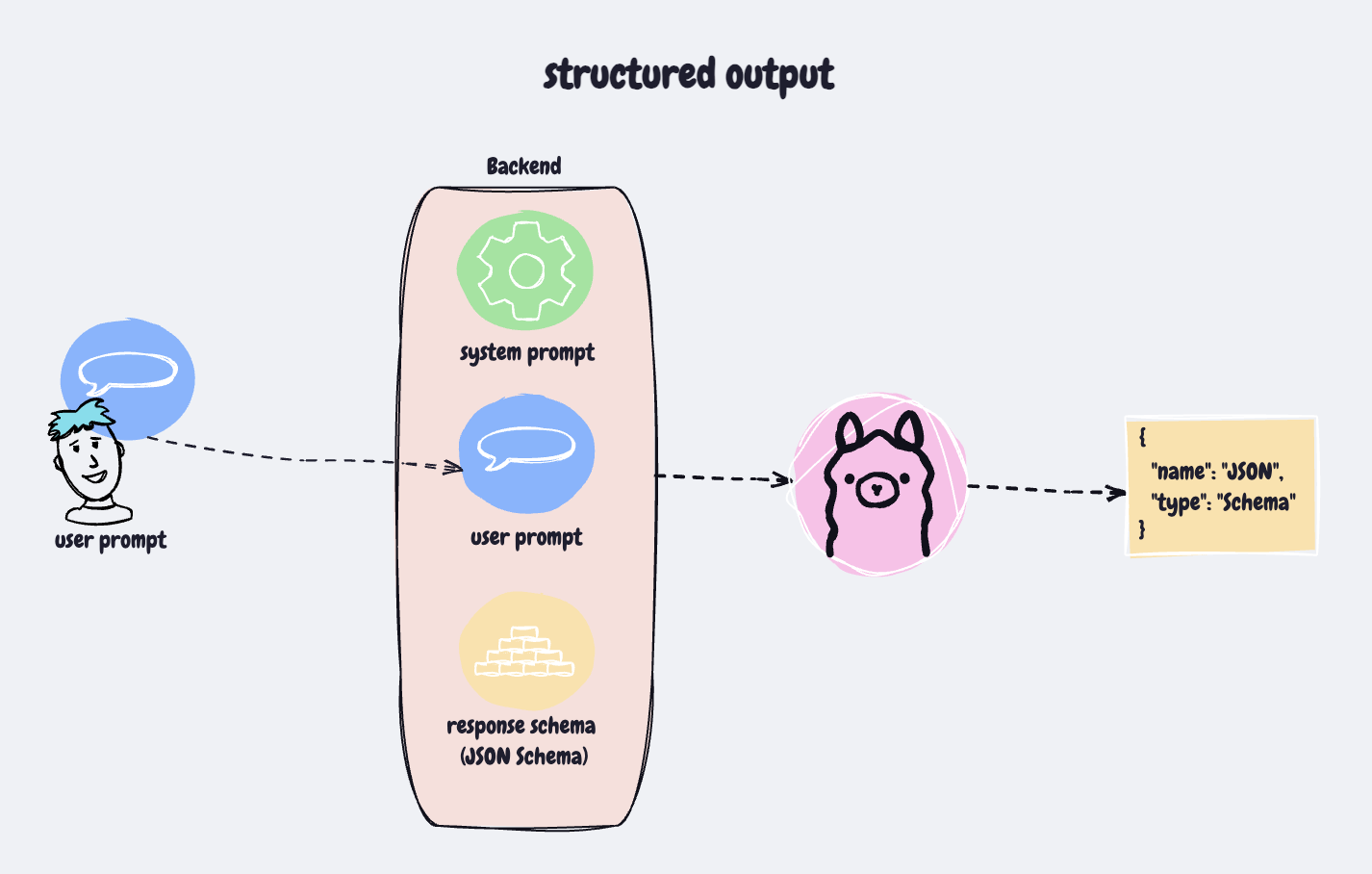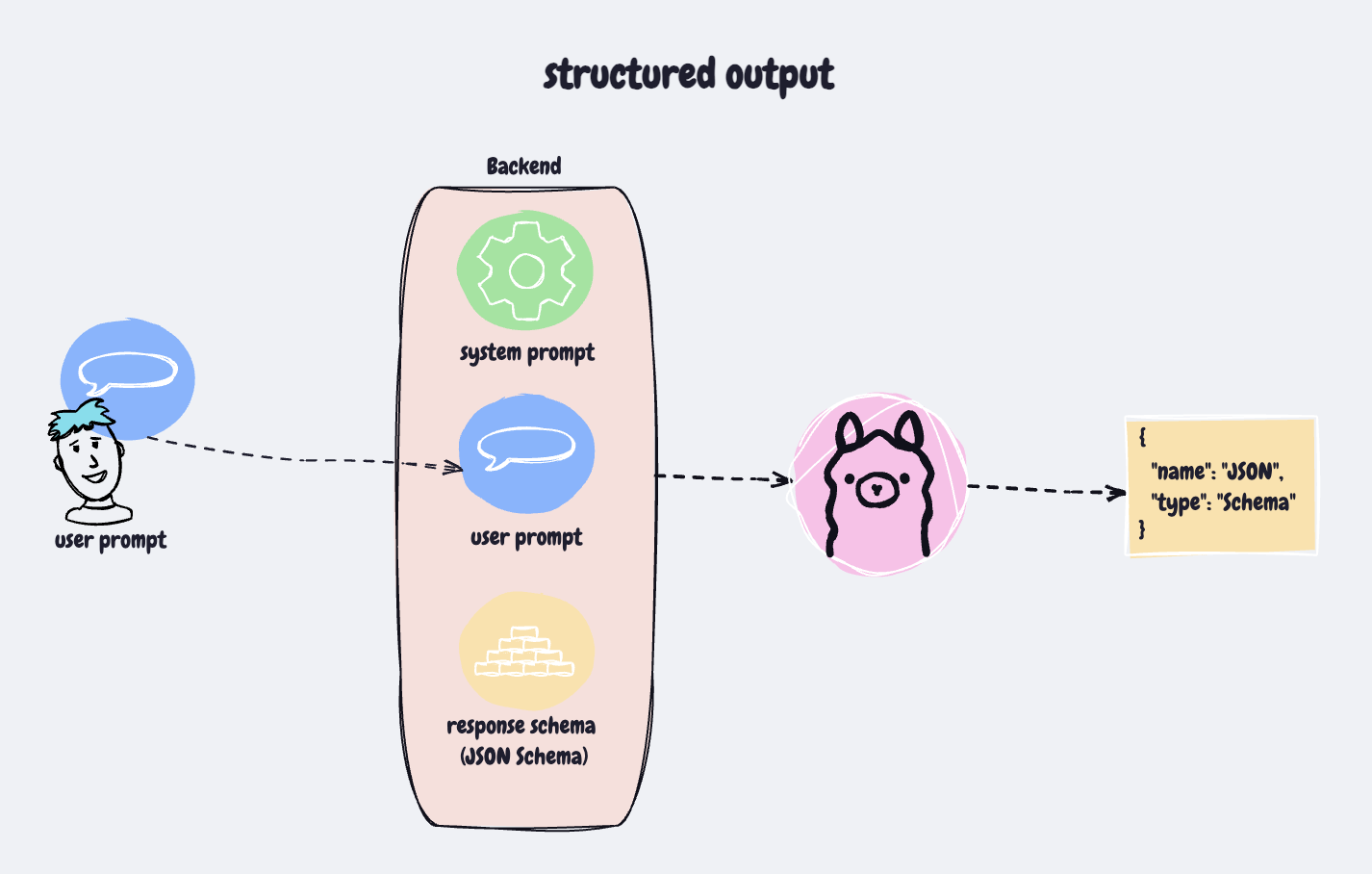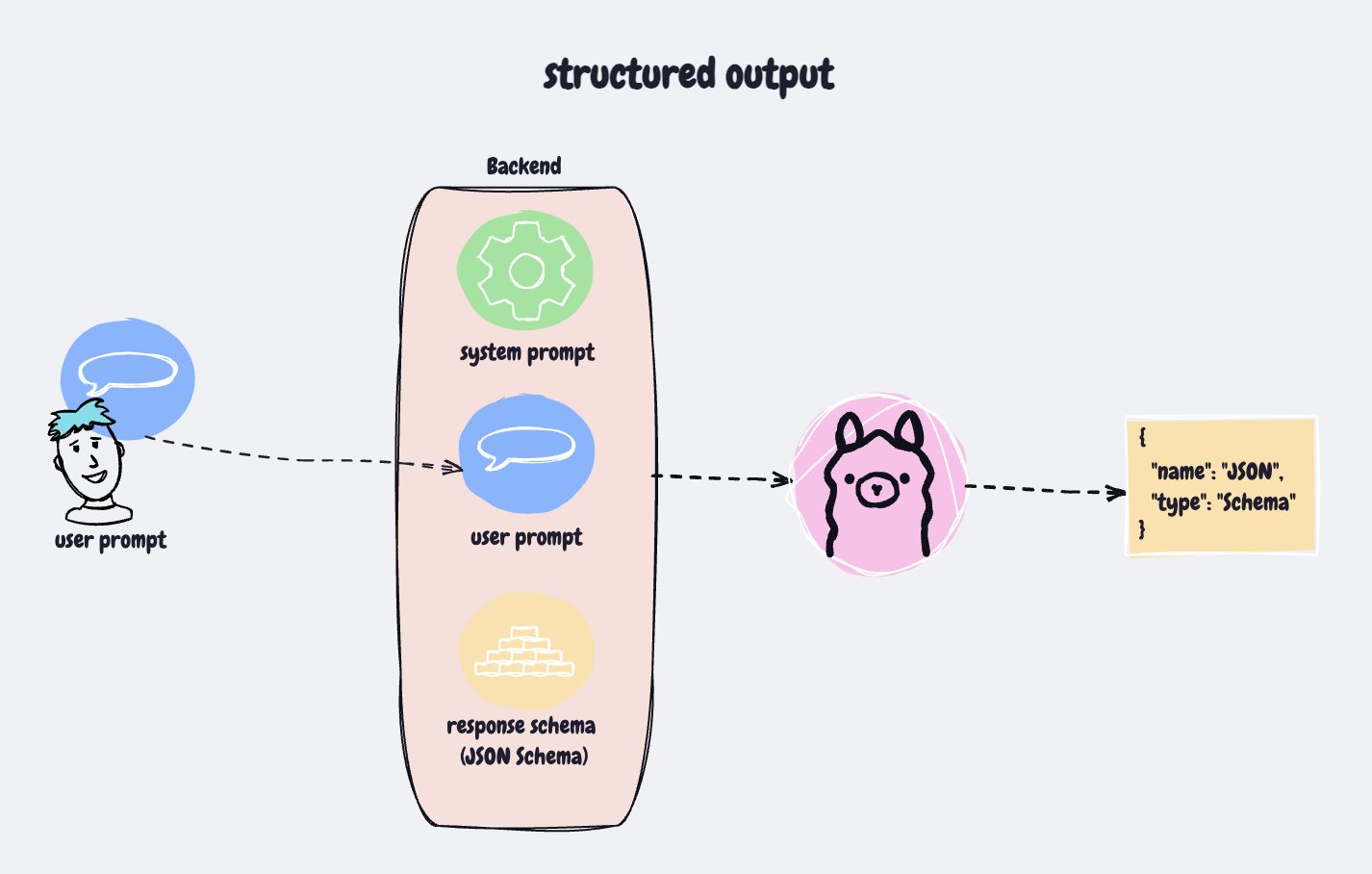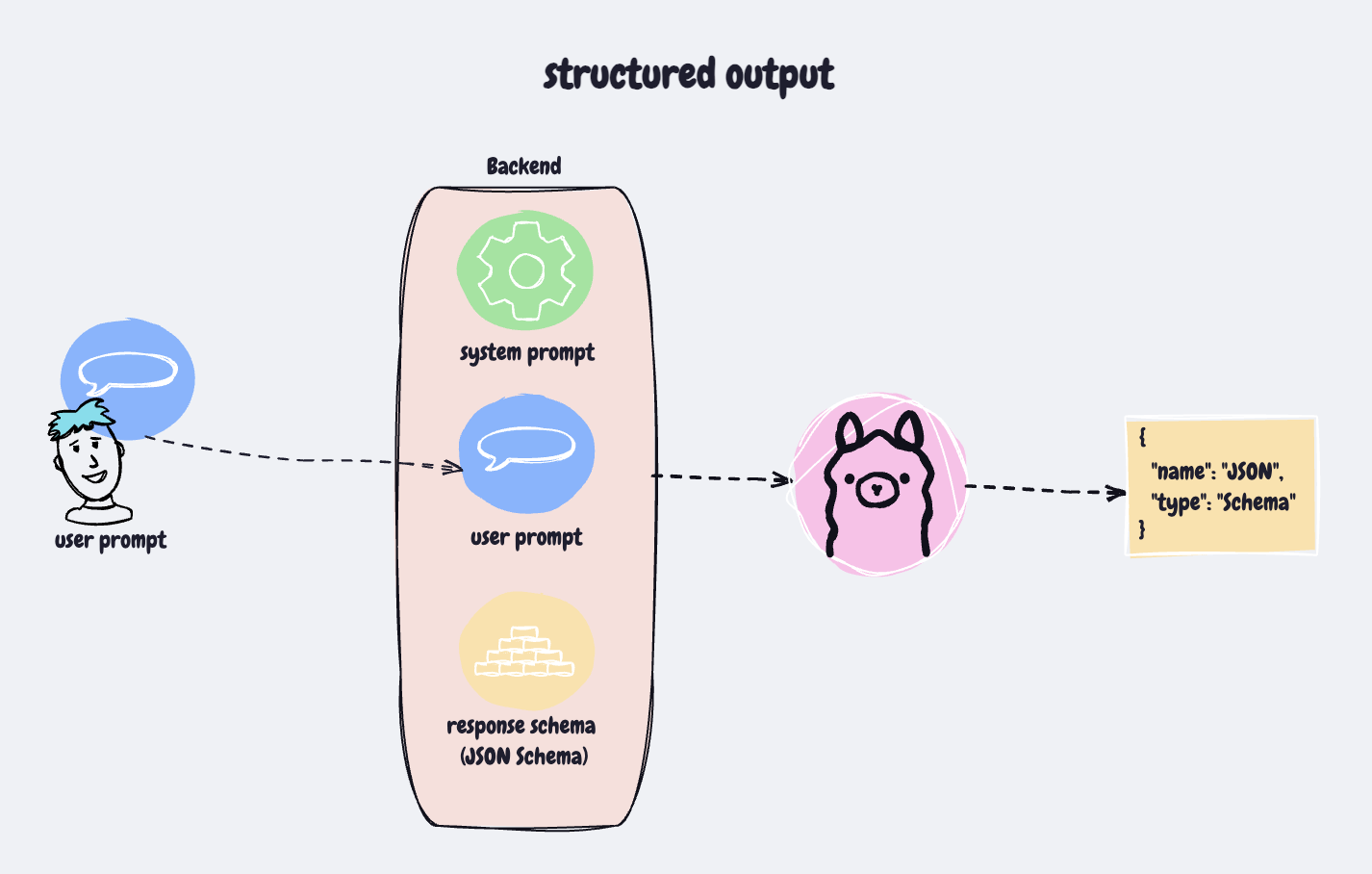
จะให้ llm response กลับมาเป็น json หน้าตาแบบไหน เราก็ต้องบอก LLM มันด้วย โดยจะต้องใช้การระบุหน้าตาผ่าน JSON Schema ครับ
โดย เราสามารถใช้ online website ช่วยได้ สำหรับ tutorial นี้ก็เพียงพออยู่นะ
แต่ในงานจริงๆผมก็แนะนำให้ใช้
เบื้องต้นใช้แค่ web นี้ก็พอ https://transform.tools/json-to-json-schema
ผมจะเขียนทั้งหมดไว้ในไฟล์เดียวเลยนะครับ
structured-output.ts
const userQuery = "What's the price of Bitcoin?";
/** json schema for crypto symbol extraction */const cryptoSymbolExtraction = { properties: { crypto_symbol: { type: "string", }, }, required: ["crypto_symbol"], type: "object",};system prompt
เรามาเตรียม system prompt กันต่อ
system prompt จะเป็นวิธีที่นิยมกันมาก คือเราจะกำหนดบทบาท และคำสั่งเบื้องต้นให้กับ llm เพื่อให้ผลลัพธ์ดีขึ้น
ในที่นี้ผมก็บอกให้มันมีหน้าที่แกะ crypto symbol น่ะแหละ ให้ออกมาเป็น json
แล้วก็ทำ single shot ด้วยการยกตัวอย่างให้มันด้วย
const systemPrompt: Prompt = { content: `You are a helpful assistant that extracts cryptocurrency symbols from user queries.Please extract the cryptocurrency symbol from the following query and output it as a JSON objectwith a single key 'crypto_symbol'.
Example:User: "How much is Ethereum?"Output: {{"crypto_symbol": "ETH"}}`, role: "system",};call llm function
ผมจะสร้าง function ที่เอาไว้ call llm ผ่าน fetch api ปกติเลยครับ
ดูได้ที่ docs ของ OpenAI
เราจะยิง POST reqeust ไปที่ http://localhost:11434/v1/chat/completions
url ผมไปเอามาจาก OpenAI API scec ครับ
เนื่องจากว่า Ollama นั้นใช้ OpenAI API Spec เป็นต้นแบบครับ ฉนั้นก็เลยใช้ api เส้นเดียวกันได้เด๊ะๆ
เพื่อนๆไปดูเพิ่มเติมได้ตรงนี้ครับ https://platform.openai.com/docs/api-reference/chat/create
ผมไปแกะ request body มาแล้ว ก็ได้ type แบบนี้ครับ
type Prompt = { role: "system" | "user" | "assistant"; content: string;};
type OpenAIChatCompletionsRequestBody = { model: string; messages: Prompt[]; response_format: { type: "json_schema"; json_schema: { name: string; schema: Record<string, unknown>; }; strict: boolean; };};ส่วนเวลาเรียกไปมันก็จะ response มาเป็น type แบบนี้ครับ
type OpenAIChatCompletionsResponse = { id: string; object: string; created: number; model: string; choices: { index: number; message: { role: string; content: string; }; finish_reason: string; }[]; usage: { prompt_tokens: number; completion_tokens: number; total_tokens: number; }; service_tier: string;};ก็จะเอามาสร้าง function แบบนี้ครับ
api key ไม่ต้องมีก็ได้นะครับ สามารถตัดออกไปได้เลย เพราะเราใช้ Ollama แต่ผมก็จะใส่ติดมาด้วย เผื่อว่าใครใช้ model ของ OpenAI มันก็ต้องมี api key ใช่มะ
ไปดู code กันก่อน เดี๋ยวผมอธิบายด้านล่างครับ
function createModelResponse( messages: Prompt[], jsonSchema: { name: string; schema: Record<string, unknown> }, model = "llama3.2:3b",) { const ollamaUrl = "http://localhost:11434/v1/chat/completions"; const apiKey = "ollama";
const headers = new Headers({ Authorization: `Bearer ${apiKey}`, "Content-Type": "application/json", });
const body: OpenAIChatCompletionsRequestBody = { messages: messages, model, response_format: { strict: true, type: "json_schema", json_schema: jsonSchema, }, };
const res = Bun.fetch(ollamaUrl, { body: JSON.stringify(body), headers, method: "POST", }) .then((res) => res.json() as Promise<OpenAIChatCompletionsResponse>) .then((res) => { return res.choices[0]?.message.content; }) .then((res) => JSON.parse(res));
return res;}เราปั้น headers ตาม code นั่นเลย
ส่วน body ก็จะมี
messagesเป็น Array ของ data แบบนี้type Prompt = { role: "system" | "user" | "assistant" content: string }นะครับmodelก็ใส่ model ที่อยากใช้ครับผมให้ default model เป็น llama3.2:3b ครับresponse_formatอันนี้แหละ เป็นตัวกำกับว่าจะต้อง response กลับมาหน้าตาแบบไหนstrict: trueคือต้องตรง format แบบเป๊ะๆ ไม่ขาดไม่เกินtype: "json_schema"เนื่องจากว่า OpenAI รองรับได้หลาย format ครับ แต่ส่วนมากเราก็จะใช้ json_schema นี่แหละjson_schemaอันนี้ก็คือ หน้าตาของcryptoSymbolExtractionที่เราทำไว้ก่อนหน้า
ทั้งหมดก็ยิงผ่าน fetch api ด้วย method choices[0].message นะครับ
สาเหตุที่เป็น choices[0] เพราะว่าปกติแล้ว api เส้นนี้มันรองรับการถามแบบ batch ครับ เช่นมีหลายๆคำถาม เราก็มัดรวมแล้วยิง POST request ทีเดียวไปเลย แต่ว่ากรณีของเรา เรามีแค่คำถามเดียวฉนั้นคำตอบมันก็เลยไปอยู่ที่ index ที่ 0 ครับ
สุดท้ายก็ parse json ครับ
ลองเรียกใช้งาน function แบบนี้ครับ
const res = await createModelResponse( [systemPrompt, { content: userQuery, role: "user" }], { name: "crypto-symbol-extraction", schema: cryptoSymbolExtraction, },);โค้ดทั้งหมดเป็นแบบนี้ครับ
structured-output
type Prompt = { role: "system" | "user" | "assistant"; content: string;};
type OpenAIChatCompletionsRequestBody = { model: string; messages: Prompt[]; response_format: { type: "json_schema"; json_schema: { name: string; schema: Record<string, unknown>; }; strict: boolean; };};
type OpenAIChatCompletionsResponse = { id: string; object: string; created: number; model: string; choices: { index: number; message: { role: string; content: string; }; finish_reason: string; }[]; usage: { prompt_tokens: number; completion_tokens: number; total_tokens: number; }; service_tier: string;};
const systemPrompt: Prompt = { content: `You are a helpful assistant that extracts cryptocurrency symbols from user queries.Please extract the cryptocurrency symbol from the following query and output it as a JSON objectwith a single key 'crypto_symbol'.
Example:User: "How much is Ethereum?"Output: {{"crypto_symbol": "ETH"}}`, role: "system",};
function createModelResponse( messages: Prompt[], jsonSchema: { name: string; schema: Record<string, unknown> }, model = "llama3.2:3b",) { const ollamaUrl = "http://localhost:11434/v1/chat/completions"; const apiKey = "ollama";
const headers = new Headers({ Authorization: `Bearer ${apiKey}`, "Content-Type": "application/json", });
const body: OpenAIChatCompletionsRequestBody = { messages: messages, model, response_format: { strict: true, type: "json_schema", json_schema: jsonSchema, }, };
const res = Bun.fetch(ollamaUrl, { body: JSON.stringify(body), headers, method: "POST", }) .then((res) => res.json() as Promise<OpenAIChatCompletionsResponse>) .then((res) => { return res.choices[0]?.message.content; }) .then((res) => JSON.parse(res));
return res;}
/** json schema for crypto symbol extraction */const cryptoSymbolExtraction = { properties: { crypto_symbol: { type: "string", }, }, required: ["crypto_symbol"], type: "object",};
const userQuery = "What's the price of Bitcoin?";
const res = await createModelResponse( [systemPrompt, { content: userQuery, role: "user" }], { name: "crypto-symbol-extraction", schema: cryptoSymbolExtraction, },);console.log("res", res);ลองสั่งรันดู
bun src/example/structured-output.tsจะได้ log ออกมาแบบนี้
res { crypto_symbol: "BTC",}ลองเปลี่ยนเป็นถาม solana บ้าง
const userQuery = "What's the price of Solana?";จะได้แบบนี้
res { crypto_symbol: "SOL",}Tool/Function calling
what is tool calling
อันนี้คือเคล็ดลับการทำ AI Agent เลยครับ ฮ่าๆ ว่าไปนั่น
อธิบายแบบลวกๆ มันคือการให้ LLM เรียกใช้ function ที่เราสร้างไว้ครับ เราสร้าง typescript function ของเราปกติเลย แล้วให้ LLM มันเรียกใช้งานครับ บางครั้งถ้าโดดไปใช้ framework บางทีมันก็อาจจะทำให้เราเข้าใจแบบที่ผมอธิบายแบบลวกๆ
จริงๆแล้ว LLM มันไม่ได้เรียกใช้ typescript function จริงๆครับ มันไม่สามารถทำแบบนั้นตรงๆจากภายใน LLM ได้ครับ
การทำงานของ tool calling ไม่ได้ซับซ้อนเลยครับ
เรามี typescript function อยู่
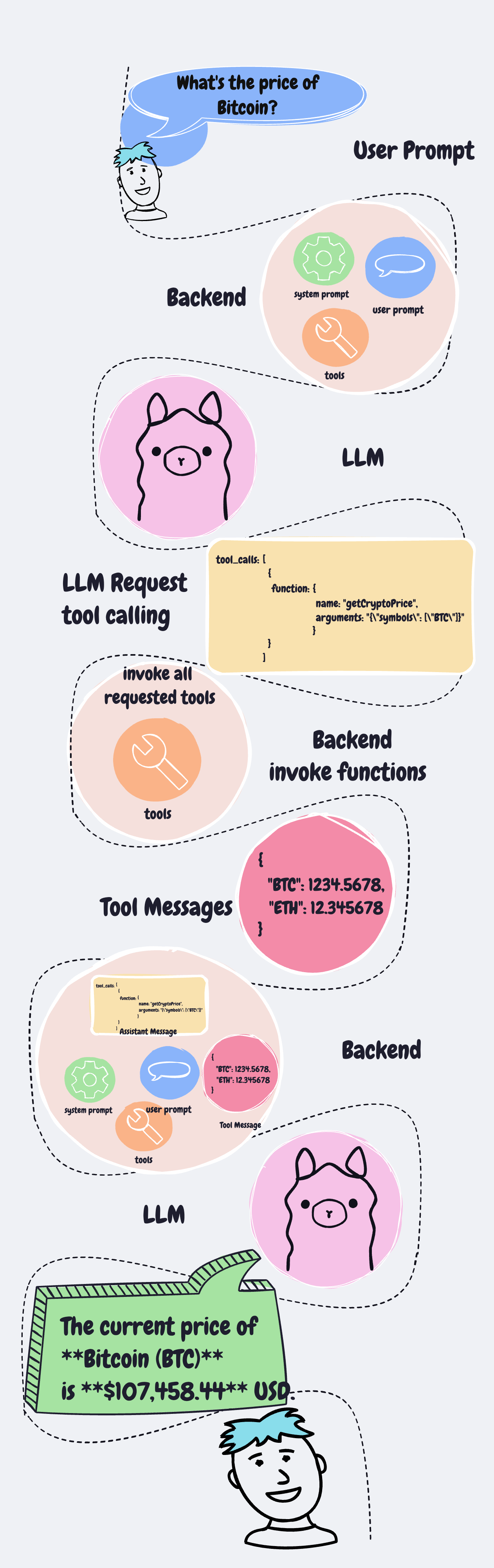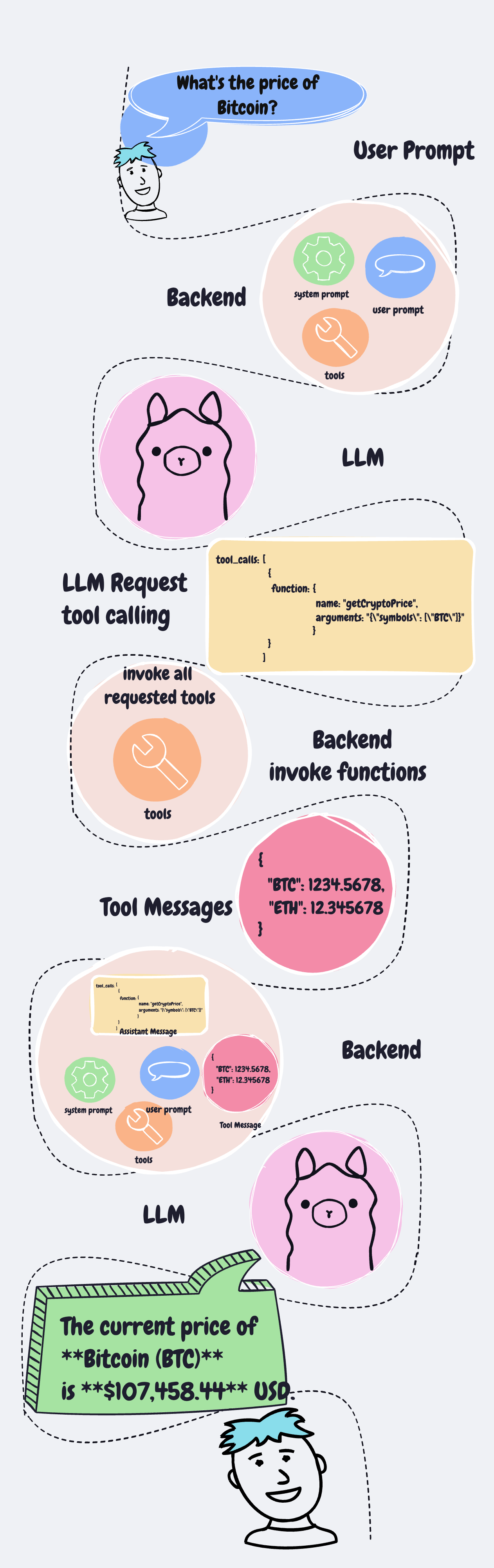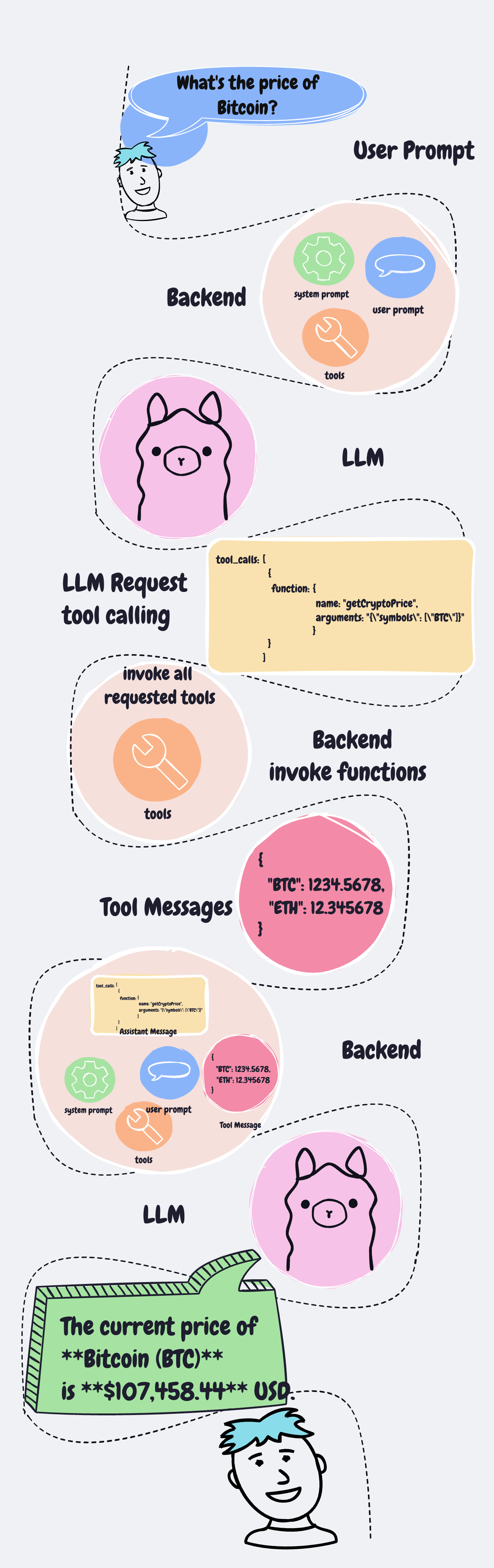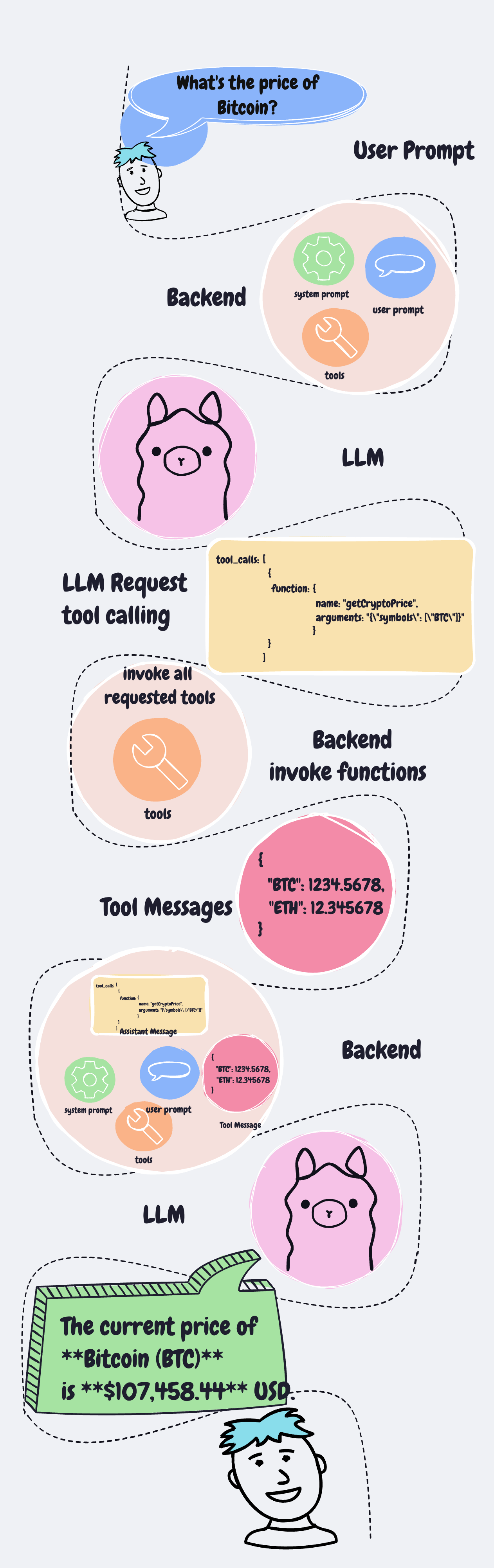
พอ user มีคำถาม ระบบของเราก็จะต้องเอาคำถามจาก user มารวมกับ typescript function ที่เรามี
แล้วส่งไปให้ LLM ทั้งหมด แล้วเดี๋ยว LLM มันจะคิดเองว่าจะต้องคำถามได้ต้องเรียก function ไหนก่อนหรือเปล่า
แล้ว LLM ก็จะตอบกลับมา
ถ้ามี function ที่จะต้องเรียกใช้ ตัว LLM จะส่ง ชื่อ function พร้อมกับ function arguments มาให้ด้วย
เราก็เอา arguments ที่ได้ไปใส่ใน function ที่เรามีจริงๆ ก็ได้ผลลัพธ์ของ function มา เราก็เอา คำถามเดิมจาก user มารวมกับ functions ที่มี (ก็ของเดิมน่ะแหละ) มารวมกับผลลัพธ์จาก function ส่งกลับไปให้ LLM อีกรอบนึง
สุดท้ายมันก็จะคืนคำตอบให้ user
start coding
มาเริ่มลงมือกันเลย เราจะทำคล้ายๆกับ structured output เลย
ผมจะส่งคำถามไปว่า
คำถามแรก
What's the price of Bitcoin?คำถามที่สอง
What's the price of Bitcoin, Ehtereum, Solana and Near?เราถามคำถามด้วยคำถามของมนุษย์ ระบบก็รับคำถามมาก่อน แต่ยังไม่ส่งให้ LLM นะ เอาคำถามมารวมกับ function ที่ใช้ดึงราคาของ crypto ก่อน แล้วเอาสองส่วนนี้ส่งไปให้ LLM แล้วก็ปล่อยให้ LLM มันคิดเองว่าจากคำถามที่ถาม ควรจะต้องเรียกใช้ functions/tools ที่มีหรือเปล่า ถ้าต้องเรียกใช้มันก็จะจัดการสร้าง arguments สำหรับ functions/tools มาให้เราเองเลย เราก็แค่เอา arguments ไปยิงใน functions ได้เลย
สุดท้ายเอาผลลัพธ์ส่งกลับไปให้ LLM อีกรอบ แล้วก็จะได้คำตอบจาก LLM เป็น crypto price agent
ทำทั้งหมดในไฟล์เดียว เพื่อความง่ายในการทำความเข้าใจครับ
แล้วก็จะใช้ model qwen3:8b ครับ ผมใช้ Macbook air M1 RAM 16GB สามารถใช้งานได้ปกติ ไม่ได้ช้าอะไรนะ
ขอเริ่มที่สร้าง type ก่อนนะ
สร้าง message type ก่อน
type UserMessage = { role: "user"; content: string;};
type SystemMessage = { role: "system"; content: string;};
type ToolMessage = { role: "tool"; content: string; tool_call_id: string;};
type ToolCall = { id: string; index: number; type: string; function: { name: string; arguments: string; };};
type AssistantMessage = { role: "assistant"; content: string; tool_calls: ToolCall[];};
type Prompt = UserMessage | SystemMessage | AssistantMessage | ToolMessage;แต่ละ type ทำอะไร ก็ตามชื่อเลย น่าจะพอเดาได้แหละ
แต่อธิบายตรงนี้นิดนึง
AssistantMessageคือ message ที่ได้จาก Model นะครับ- property
tool_callsถ้ามี data ในส่วนนี้หมายความว่า LLM ต้องการให้เรา เอา data ในนี้ไปเรียกใช้ functions ต่างๆ ซึ่ง data นี้เนี่ย LLM เป็นคนส่งมานะ มันส่ง data หน้าตาแบบที่เห็นใน typeToolCallนั่นแหละ
- property
ToolMessageคือ message ที่ได้จากการไปเรียกใช้ tool calling
ส่วน Prompt ก็แค่เอาทั้งหมดมา union กัน
ต่อมาก็จะสร้าง POST request เพื่อยิง user message พร้อมกับ tools ที่เรามีไปให้ LLM
ไปดู api document ได้ที่ https://platform.openai.com/docs/guides/function-calling?api-mode=chat
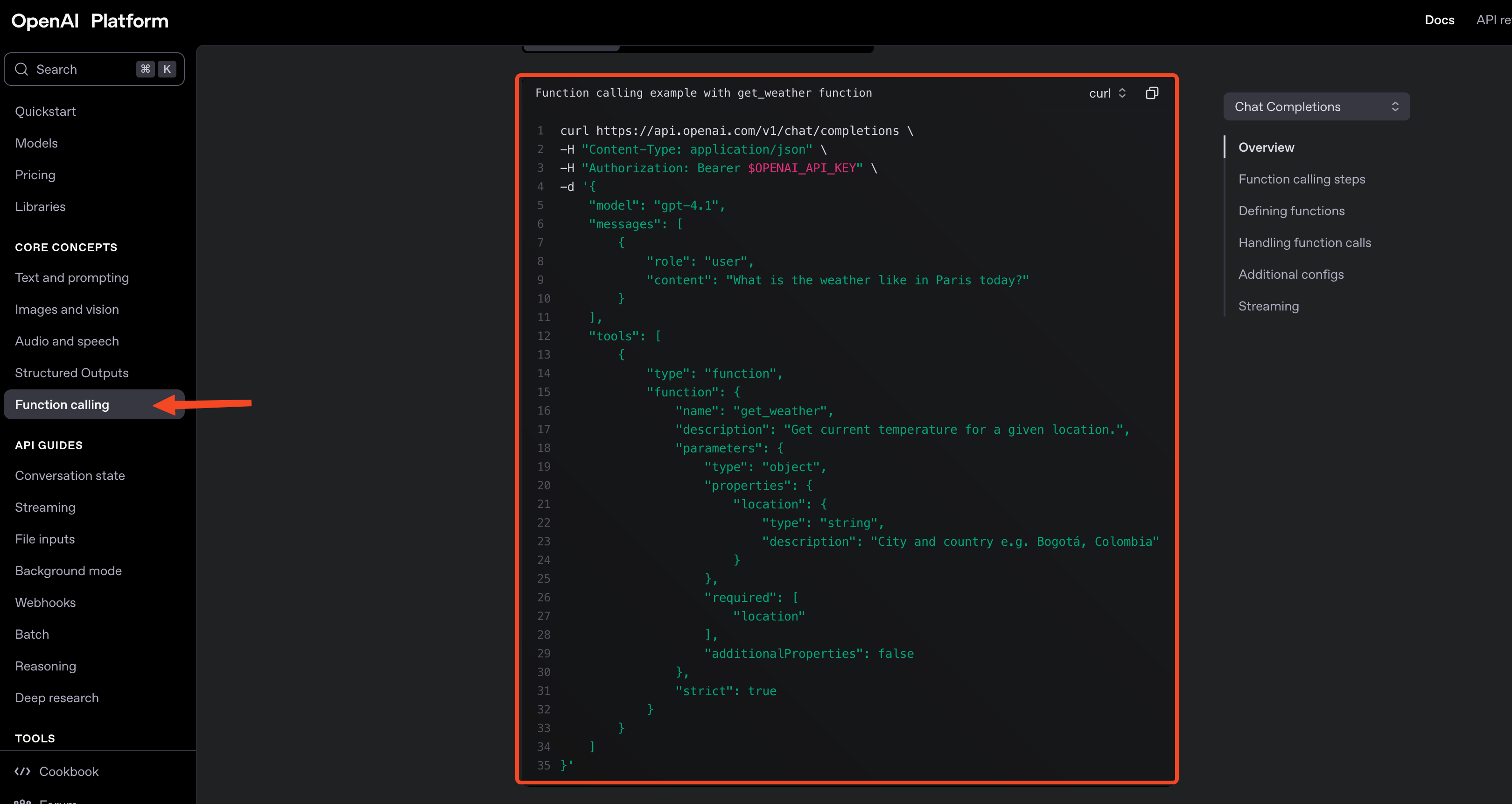
ผมก็แกะ request body ออกมาเป็น type แบบนี้
type Tool = { type: "function"; function: { name: string; description: string; parameters: Record<string, unknown>; }; strict: boolean;};
type ChatCompletionRequest = { model: string; messages: Prompt[]; tools: Tool[];};ส่วน Response type ผมก็ไปแกะมาแล้ว จะเป็นแบบนี้ เดี๋ยวอธิบายด้านล่างนะ
type Choice = { index: number; message: AssistantMessage; finish_reason: "tool_calls" | "stop";};
type ChatCompletionResponse = { id: string; object: string; created: number; model: string; system_fingerprint: string; choices: Choice[]; usage: { prompt_tokens: number; completion_tokens: number; total_tokens: number; };};type Choice อันนี้เราต้องสนใจเป็นพิเศษ
ในส่วนของ finish_reason เป็น literal type นะ
ถ้าเป็น
stopคือ LLM ตอบคำถามได้หมดเลย ไม่ต้องการให้ไปเรียกใช้ tools อะไรทั้งนั้นtool_callsคือ LLM ต้องการให้เราไปเรียกใช้ functions อะไรบางอย่าง เพื่อที่จะได้ตอบคำถามได้ ส่วนจะเรียกใช้ functions อะไรบ้างนั้นจะอยู่ใน propertymessageนะ- ส่วนอื่นๆก็ไม่ได้มีอะไรสำคัญ แต่ก็เผื่อมีประโยชน์ก็ใส่ติดๆมา
แล้วเราก็มาสร้าง function ที่จะเอาไว้ยิง request กันเลยแบบนี้ เดี๋ยวอธิบายโค้ดด้านล่างนะ
function createModelResponse( messages: Prompt[], tools: Omit<Tool, "type" | "strict">[], model = "qwen3:8b",) { const ollamaUrl = "http://localhost:11434/v1/chat/completions"; const apiKey = "ollama";
const headers = new Headers({ Authorization: `Bearer ${apiKey}`, "Content-Type": "application/json", });
const body: ChatCompletionRequest = { messages, model, tools: tools.map((t) => ({ ...t, strict: true, type: "function" })), };
const res = Bun.fetch(ollamaUrl, { body: JSON.stringify(body), headers, method: "POST", }) .then((res) => res.json() as Promise<ChatCompletionResponse>) .then((res) => { return res.choices[0]; });
return res;}- จะใช้ model
qwen3:8bเป็น default นะ - ยิง api ไปที่ path
/chat/completionsเหมือนเดิมนะ - api key ไม่ต้องมีก็ได้ แต่ผมใส่มากันลืมเผื่อว่าเปลี่ยนไปใช้ OpenAI model
- สร้าง Headers ตามโค้ดเลยไม่ได้ซับซ้อน
- มาที่ body ก็ใส่ตาม type
ChatCompletionRequestที่เราทำไว้ก่อนหน้าเลย- ตรงนี้ผมเนื่องจากว่าใน parameters ใช้ Omit เพื่อเอา property
typeกับstrictออกไป ก็เลยต้องเติมตรงนี้ผ่าน map อีกที ที่ทำแบบนี้เพื่อให้เรียกใช้ function ได้สะดวกขึ้น
- ตรงนี้ผมเนื่องจากว่าใน parameters ใช้ Omit เพื่อเอา property
- เรียกใช้
Bun.fetchได้เลย
fetch crypto price function
ต่อไปก็จะไปสร้าง function fetch crypto price นะครับ
เดี๋ยวค่อยเอามารวมกันทีหลัง
function getCryptoPrice({ symbols }: { symbols: string[] }) { const searchParams = new URLSearchParams({ base: "USD", currencies: symbols.join(","), }); const url = "https://api.kucoin.com/api/v1/prices";
const data = Bun.fetch(`${url}?${searchParams.toString()}`, { method: "GET", }) .then( (res) => res.json() as Promise<{ code: string; data: Record<string, string>; }>, ) .then((res) => res.data);
return data;}function ด้านบนไม่มีอะไรพิเศษ แค่เอาไว้ยิง api ปกติเลย
แต่ว่า เราไม่สามารถเอา function นี้ส่งไปให้ LLM ได้ เราต้องแปลงมันไปเป็น text ซะก่อนครับ
ซึ่งสิ่งที่ LLM ต้องการคือ
- ชื่อ function
- รายละเอียดของ parameters ในรูปของ JSON Schema ครับ
ซึ่งมี type เป็น
Toolที่เราได้ทำไปแล้วน่ะแหละ อะเอามาให้ดูอีกที
type Tool = { type: "function"; function: { name: string; description: string; parameters: Record<string, unknown>; }; strict: boolean;};สิ่งที่เราจะทำ ไม่ได้จะเอา function มาแปลงเป็น text อะไร
สร้าง text ชุดใหม่ขึ้นมาเพื่ออธิบายเกี่ยวกับตัว function ล้อไปตามสิ่งที่ LLM มันต้องการ
ผมก็สร้างมาแบบนี้
เดี๋ยวอธิบายด้านล่าง
const getCryptoPriceTool: Omit<Tool, "type" | "strict"> = { function: { description: `this is crypto cryptocurrency price api written in typescriptthis function will return the price of the cryptocurrency symbol providedplease provide symbols as array of string
example of parameters: {"symbol": ["BTC","ETH"]}`, name: "getCryptoPrice", parameters: { properties: { symbols: { items: { type: "string", }, type: "array", }, }, required: ["symbols"], type: "object", }, },};จากโค้ดด้านบนผมใส่ description เพื่ออธิบายว่า function นี้ทำอะไร อันนี้สำคัญนะ
ทำให้ LLM มันตัดสินใจได้ถูกต้องมากขึ้นว่าจะเรียกใช้ function นี้ไหม รวมถึง argument ที่จะถูกต้องมากขึ้นด้วย
ส่วนชื่อ function ก็ไม่จำเป็นต้องเหมือนกับชื่อ function จริงๆ ก็ได้ อยู่ที่เราจะ handle ยังไง แต่เพื่อไม่ให้งง ผมก็ใส่ให้มันเหมือนกันดีกว่า
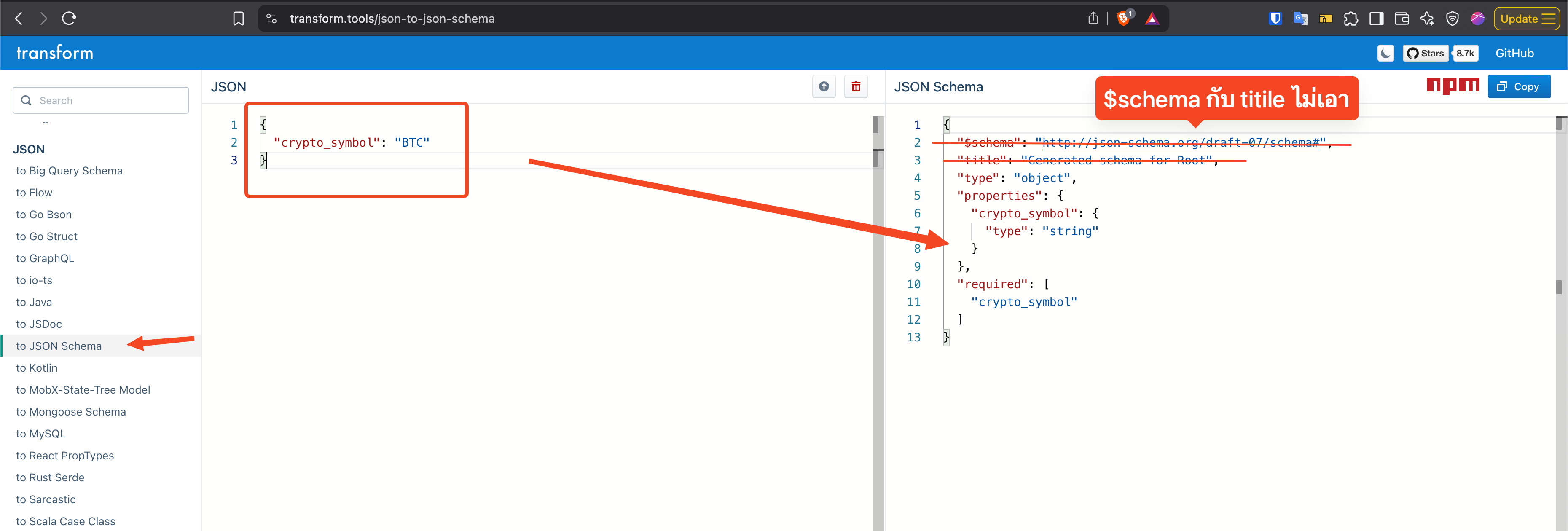
ส่วนของ parameter อันนี้แหละต้องทำเป็น JSON Schema ซึ่งผมก็ไปที่เดิม แล้วทำเหมือนในภาพด้านล่างนะ
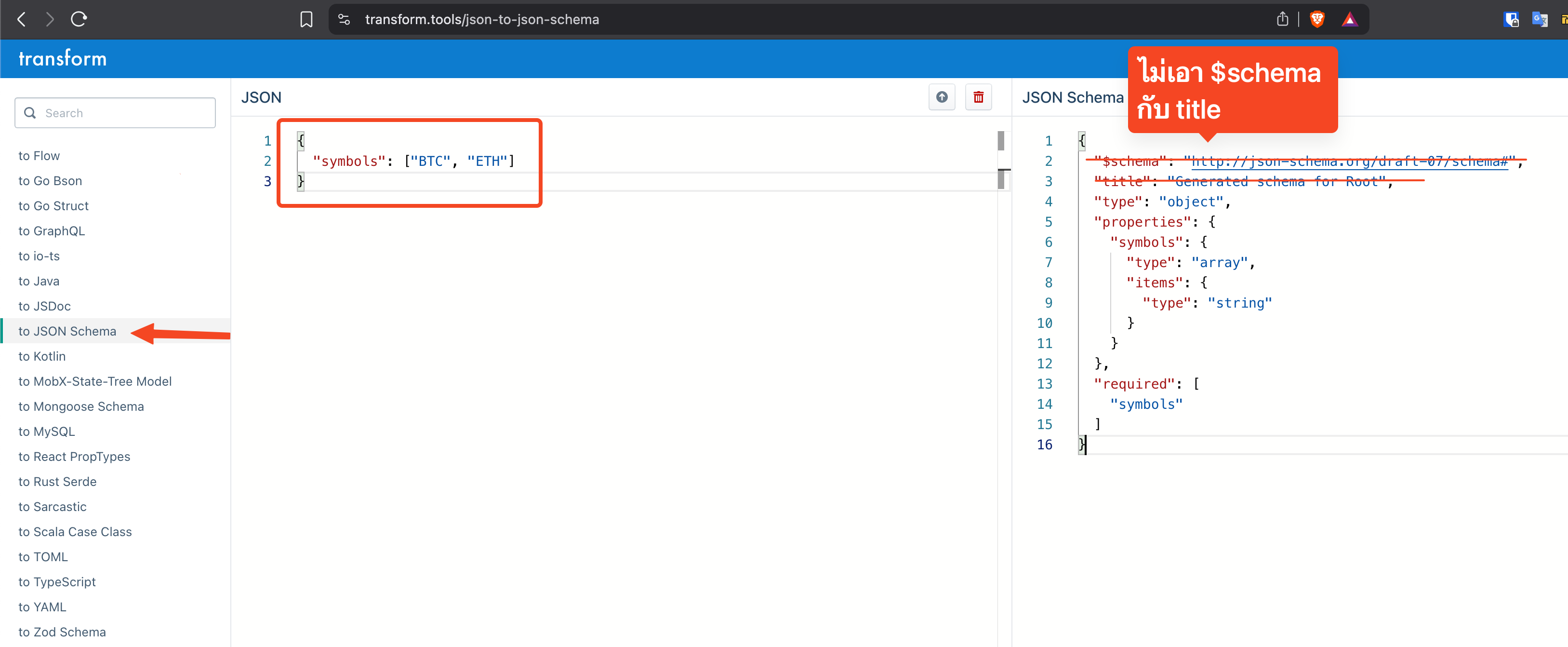
ก็เลยเป็นที่มาของโค้ดด้านบนนะครับ
ลองมาเรียกใช้กันก่อน ดูซิว่า LLM มันต้องการให้เรียกใช้ functions เพื่อตอบคำถามไหม
ผมจะสร้าง function main() มาก่อน
แล้วเรียกใช้งานเลย
เดี๋ยวการทำงานที่เหลือจะใส่ไว้ใน main() นี่แหละ
async function main() {}
main();มาเขียนต่อ เดี๋ยวอธิบายด้านล่างนะ
async function main() { const systemPrompt: SystemMessage = { content: "You are a helpful cryptocurrency price fetching assistant.", role: "system", } const userQuery = "What's the price of Bitcoin?" // const userQuery = "What's the price of Bitcoin, Ehtereum, Solana and Near?"
const initialMessages: Prompt[] = [systemPrompt, { content: userQuery, role: "user" }]
const availableTools: (Omit<Tool, "type" | "strict">)[] = [getCryptoPriceTool]
const initialModelResponse = await createModelResponse( initialMessages, availableTools, )
console.log("initialModelResponse", initialModelResponse) console.log("json", JSON.stringify(initialModelResponse))
if (initialModelResponse === undefined) return ""
if (initialModelResponse.finish_reason === "stop") { return initialModelResponse.message.content }เราสร้าง system prompt systemPrompt
สร้าง user prompt userQuery
เอา prompt ทั้งสองอันมารวมกัน
สร้าง tools array availableTools
แล้วเรียก function createModelResponse()
ถ้า response เป็น undefined ต้อง handle นะ อาจจะบอก user ว่ามีปัญหาอะไรสักอย่างทำให้ไม่ได้ response
แต่ในที่นี้ผม return "" ซึ่งก็ไม่ควรนะ
และถ้าใน response มี finish_reason === "stop" ก็คือไม่ต้องการให้เรียกใช้ tools อะไร ก็เอา content ส่งกลับไปให้ user ได้เลย
ลองไปยิงดูก่อน
bun src/example/tool-calling.tsจะได้แบบนี้
initialModelResponse { index: 0, message: { role: "assistant", content: "<think>\nOkay, the user is asking for the price of Bitcoin. Let me check the tools available. There's a function called getCryptoPrice that takes an array of symbols. The user mentioned Bitcoin, which is usually represented by the symbol BTC. So I need to call that function with [\"BTC\"] as the symbols parameter. I should make sure the arguments are correctly formatted as a JSON object within the tool_call tags. Let me double-check the function's required parameters—yes, it's an array of strings. Alright, that's all I need.\n</think>\n\n", tool_calls: [ { id: "call_kxphrhlj", index: 0, type: "function", function: { name: "getCryptoPrice", arguments: "{\"symbols\":[\"BTC\"]}", }, } ], }, finish_reason: "tool_calls",}มี <think></think> ด้วยเนื่องจากว่า Qwen3 มันมี reasoning ด้วยอะนะ
จะเห็นว่า finish_reason เป็น tool_calls ตรงนี้แหละที่บอกเราว่าต้องการให้ไปเรียกใช้ function ก่อน แล้วจึงจะตอบคำถามได้
จะเห็นว่ามี property tool_calls ด้วย ตรงนี้แหละ ที่บอกเราว่าเรียก functions อะไรบ้าง แต่ละตัวมี arguments อะไรบ้าง
ตรง arguments จะเห็นว่ามันเป็น string นะ เดี๋ยวเราต้องเอามา JSON.parse() อีกทีนะ
มาลุยกันต่อ
ทำเพิ่มส่วนล่างนะ
async function main() {26 collapsed lines
const systemPrompt: SystemMessage = { content: "You are a helpful cryptocurrency price fetching assistant.", role: "system", }; const userQuery = "What's the price of Bitcoin?"; // const userQuery = "What's the price of Bitcoin, Ehtereum, Solana and Near?" const initialMessages: Prompt[] = [ systemPrompt, { content: userQuery, role: "user" }, ];
const availableTools: Omit<Tool, "type" | "strict">[] = [getCryptoPriceTool];
const initialModelResponse = await createModelResponse( initialMessages, availableTools, );
console.log("initialModelResponse", initialModelResponse); console.log("json", JSON.stringify(initialModelResponse));
if (initialModelResponse === undefined) return "";
if (initialModelResponse.finish_reason === "stop") { return initialModelResponse.message.content; }
const toolCalls = initialModelResponse.message.tool_calls;
const callToolPromises = toolCalls.map(async (tool) => { const args = JSON.parse(tool.function.arguments);
console.log(tool.function.arguments, { args });
if (tool.function.name === "getCryptoPrice") { const result = await getCryptoPrice(args); const msg: ToolMessage = { content: JSON.stringify(result), role: "tool", tool_call_id: tool.id, }; return msg; } });
const toolMessages = await Promise.all(callToolPromises).then((data) => data.filter((msgOrUndefined) => !!msgOrUndefined), );
console.log("toolMessages", toolMessages);}ถ้าผ่าน fish_reason === "stop" มาได้นั่นหมายความว่า เราต้องไปเรียกใช้ tools แน่ๆแล้ว
ก็เลยดึง tools ออกมาไว้ในตัวแปร toolCalls ก่อน
ซึ่ง toolCalls เนี่ยอาจจะมีหลาย functions หลาย tools ก็ได้นะ มันก็เลยเป็น array อะนะ
แล้วก็เอามา loop เลย
ใน loop ก็ยิง function ซะ
ใน code ผมใช้ .map() แล้ว return Promise นะ
การทำงานก็คือ
- ถ้าเจอว่า function ที่ LLM ร้องขอให้เรียกใช้ ชื่อว่า
getCryptoPriceก็จะไปเรียก functiongetCryptoPrice - เอา arguments มา
JSON.parseแล้วส่งเข้าไปเป็น arguments ใน function ได้เลย - พอได้ result มา เราต้องแปลงให้เป็น type
ToolMessageก่อน เพื่อให้ LLM มันเข้าใจ- แนบ
tool_call_idไปด้วย LLM มันจะได้รู้ว่าเป็นคำตอบที่มาจาก function ไหนตามที่มันร้องขอ
- แนบ
- สุดท้ายด้านล่าง ก็ใช้
Promise.all()แล้ว filter คำตอบที่เป็นundefinedออกไป
ที่เป็นundefinedได้ก็เพราะว่า มันก็มีโอกาสที่ LLM จะร้องขอให้เราทำ function ที่เราไม่ได้ส่งให้มันไป อาการหลอนอะแหละ เราก็จะ returnundefinedจาก map callback ใช่มะ ตรงนี้ถ้าใช้ Match expression น่าจะอ่านง่ายกว่า แต่ผมไม่อยากใส่ Effect เข้ามา กลัวมันไม่ Basic ฮ่าๆ
มาลองรันอีกรอบ ตอนรันมันจะเหมือนค้างๆนานๆอะนะ จริงๆคือมัน thinking อยู่นะ ถ้าใช้ stream response จะดีกว่า แต่เดี๋ยวจะไม่ Basic อะสิ
bun src/example/tool-calling.tsจะได้แบบนี้ ใน console
toolMessages [ { content: "{\"BTC\":\"107438.2427495775528295\"}", role: "tool", tool_call_id: "call_p5ntimdg", }]มาทำกันต่ออีกนิดนึง
เราต้องเอาคำตอบที่ได้จาก functions ส่งกลับไปให้ LLM อีกรอบนึง
async function main() {49 collapsed lines
const systemPrompt: SystemMessage = { content: "You are a helpful cryptocurrency price fetching assistant.", role: "system", }; const userQuery = "What's the price of Bitcoin?"; // const userQuery = "What's the price of Bitcoin, Ehtereum, Solana and Near?" const initialMessages: Prompt[] = [ systemPrompt, { content: userQuery, role: "user" }, ];
const availableTools: Omit<Tool, "type" | "strict">[] = [getCryptoPriceTool];
const initialModelResponse = await createModelResponse( initialMessages, availableTools, );
console.log("initialModelResponse", initialModelResponse); console.log("json", JSON.stringify(initialModelResponse));
if (initialModelResponse === undefined) return "";
if (initialModelResponse.finish_reason === "stop") { return initialModelResponse.message.content; }
const toolCalls = initialModelResponse.message.tool_calls;
const callToolPromises = toolCalls.map(async (tool) => { const args = JSON.parse(tool.function.arguments);
console.log(tool.function.arguments, { args });
if (tool.function.name === "getCryptoPrice") { const result = await getCryptoPrice(args); const msg: ToolMessage = { content: JSON.stringify(result), role: "tool", tool_call_id: tool.id, }; return msg; } });
const toolMessages = await Promise.all(callToolPromises).then((data) => data.filter((msgOrUndefined) => !!msgOrUndefined), );
console.log("toolMessages", toolMessages);
const finalModelResponse = await createModelResponse( [...initialMessages, initialModelResponse.message, ...toolMessages], availableTools, );
const content = stripThinkTags(finalModelResponse?.message.content || ""); console.log("content response: ", content);}function stripThinkTags(content: string) { const thinkStepPattern = /<think>[\s\S]*?<\/think>/g; return content.replace(thinkStepPattern, "").trim();}ที่ทำเพิ่มก็แค่ เอา messages เดิมที่เคยส่งไปให้ LLM ครั้งแรก (มี System prompt + User prompt) รวมกับ response ที่ได้จาก LLM ด้วยนะ (Assistant message) แล้วก็ใส่ result จาก functions ของเราด้วย (Tool Message)
แล้วพอได้ result ตัว Qwen3 มันจะส่งตัว thinking มาด้วย ซึ่งเราไม่ได้ต้องการ ผมก็เลยสร้าง function เพื่อลบ thinking ออกไป เหลือแค่คำตอบเน้นๆ
มาลองรันอีกที จะได้แบบนี้
content response: The current price of **Bitcoin (BTC)** is **$107,458.44** USD. This price is based on the latest data available. Let me know if you'd like updates or other cryptocurrencies!Conclusion
หวังว่าเพื่อนน่าจะเห็นภาพว่า AI Agent เบื้องหลังมันทำงานยังไงนะครับ
การประยุกต์ใช้ก็ขึ้นอยู่กับว่าจินตนาการของเพื่อนๆแล้วละว่า functions ที่เราสร้างอยากให้มันทำอะไร
และไม่จำเป็นต้องยึดติดกับ python หรือ typescript ก็ได้เพียงแค่เราใช้ REST Api ได้ก็ทำ AI Agent ได้แล้ว
แต่ผมก็คิดว่าถ้าอยากสร้าง AI Agent ได้เร็ว การใช้ Framework จะทำได้เร็วกว่ามาก
พื้นฐานก็สำคัญนะ
หลังจาก blog นี้ผมหวังว่าตอนใช้ Framework เพื่อนๆก็น่าจะเข้าใจได้ง่ายขึ้นนะครับ
ขอบคุณที่อ่านจนจบครับ 🙏🏼
ใครมีคำถามหรือข้อเสนอแนะก็ inbox มาคุยกันได้ครับ